My latest TinyTapeout project is ttsky26a, a compact open-silicon artifact for a compiler question I keep coming back to: how far can I keep arithmetic decisions visible before they collapse into opaque RTL? It also fits directly into the thread running across my publications, my projects, and my broader work on arithmetic-aware compilation.
The chip is called tt_um_lledoux_s3fdp_seqcomb. It wraps a generated floating-point accumulation core in a simple byte-stream interface, but the interesting part is the path that produces it: an MLIR loop is specialized, lowered through my arithmetic-oriented flow, passed through CIRCT, and exported as SystemVerilog for TinyTapeout on SKY130.

Why This One Matters
For integer-heavy hardware flows, the path from high-level IR to explicit structure is already reasonably well served. Floating-point is where things still tend to disappear behind generators or black-box boundaries, exactly when the useful tradeoffs become concrete: area, latency, rounding points, specialization, and structure that could still be optimized.
This TinyTapeout project is a small answer to that gap. Instead of treating the arithmetic block as something external that only appears at the very end, I wanted the generated datapath to remain compiler-visible through the lowering stages. It is closely aligned with my paper Towards Optimized Arithmetic Circuits with MLIR, the EuroLLVM poster Towards Multi-Level Arithmetic Optimizations, the more recent presentation Arithmetic Lowering with Emeraude-MLIR: Bridging Tensor and DSP Kernels to Silicon Datapaths, and the broader background collected in my PhD thesis Floating-Point Arithmetic Paradigms for High-Performance Computing: Software Algorithms and Hardware Designs.
From MLIR Loop to Chip
The source kernel is intentionally small enough to fit TinyTapeout, but still representative of the kind of multiply-add patterns I care about:
scf.for %k = %c0 to %c2 step %c1 {
%x = memref.load %a[%k] : memref<2xf32>
%y = memref.load %b[%k] : memref<2xf32>
%acc = memref.load %c[%c0] : memref<2xf32>
%m = arith.mulf %x, %y : f32
%s = arith.addf %acc, %m : f32
memref.store %s, %c[%c0] : memref<2xf32>
}
In the flow used here, that pattern is recognized and lowered toward a specialized S3FDP accumulation core instead of dissolving into generic floating-point logic. The repository keeps multiple IR snapshots, so the structural transition stays inspectable rather than hidden. The exact input kernel lives in flow/mlir/s3fdp_loop_accum.mlir, and the generated stages can be inspected directly in generated/ir-stages.
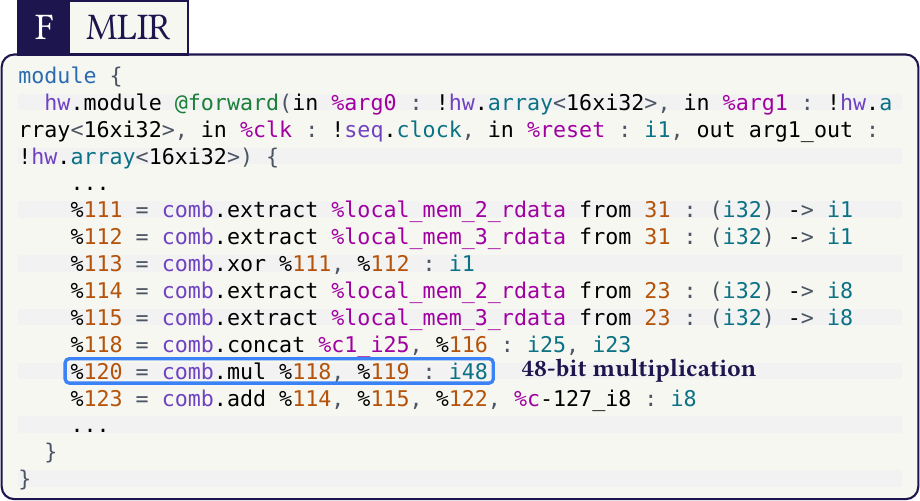
The stack behind this artifact is roughly:
-
MLIRfor the source representation and pattern capture -
emeraude-mlirfor arithmetic-aware lowering and specialization - my
FloPoCo2development branch for compiler-visible arithmetic generation -
CIRCTfor hardware lowering and SystemVerilog export - a TinyTapeout wrapper plus cocotb testbench to make the result testable and tapeout-ready
TinyTapeout Interface
The wrapper keeps things simple. The design consumes a 20-byte input frame, runs the accumulation core, then streams the 32-bit result back out over four bytes. The implementation is visible in src/project.v and the generated arithmetic core in src/generated/s3fdp_core.sv:
-
a[2]as twof32values -
b[2]as twof32values -
c0as the initialf32seed -
3execution cycles -
4output bytes
That gives a full slot cadence of 27 cycles per transaction.
This is also why I like TinyTapeout as a medium. The area is small and the protocol is constrained, but that pressure is useful: if a compiler idea still survives in that format, it usually means the path is honest. In that sense this project also extends some earlier open-silicon directions in my work, including LLMMMM: Large Language Models Matrix-Matrix Multiplications Characterization on Open Silicon and The Grafted Superset Approach: Bridging Python to Silicon with Asynchronous Compilation and Beyond.
Reproducible On Purpose
The repository includes the generated SystemVerilog, the intermediate IR stages, the wrapper, and the cocotb-based testbench. That was important to me. The value of this tapeout is not only the final silicon, but the fact that the lowering path remains visible and reproducible all the way through the artifact.
If you want to inspect it directly, the repo is here: Bynaryman/ttsky26a. For the surrounding context, you can also browse my HAL profile, my publications page, and related project pages such as OSFNTC and SUF.
Related Reading
- Towards Optimized Arithmetic Circuits with MLIR explains the arithmetic-compiler direction this tapeout is pushing toward silicon.
- Towards Multi-Level Arithmetic Optimizations gives the EuroLLVM view of the same multi-level optimization thread.
- Arithmetic Lowering with Emeraude-MLIR: Bridging Tensor and DSP Kernels to Silicon Datapaths connects the MLIR lowering story to tensor and DSP kernels.
- Floating-Point Arithmetic Paradigms for High-Performance Computing: Software Algorithms and Hardware Designs is the thesis-level background behind many of these arithmetic choices.
- An Open-Source Framework for Efficient Numerically-Tailored Computations and the related OSFNTC project page cover the earlier numerically-tailored hardware generation line.
- LLMMMM: Large Language Models Matrix-Matrix Multiplications Characterization on Open Silicon gives the broader LLM-to-open-silicon context behind some of the workload motivation.
- FloPoCo and MLIR: a Multi-Level Compilation Framework for Many Intents reflects the same compiler-generator interface from the seminar side.
- Upstream compiler pieces touched by this work include CIRCT’s convert-index-to-uint and multi-result
scf.index_switchsupport.